Recently, we were tasked with implementing a process that solely keeps the most recent 18 months of data in a client Redshift account in order to minimise their AWS costs. Furthermore, the process was required to ensure that all historical data was maintained in Glacier and to minimise pipeline disruption (i.e run within a day!). Working on the task led to us changing the way we approach this problem and as a result we decided to document our journey from using unload to using deep copy statements to achieve this.
The Initial Approach
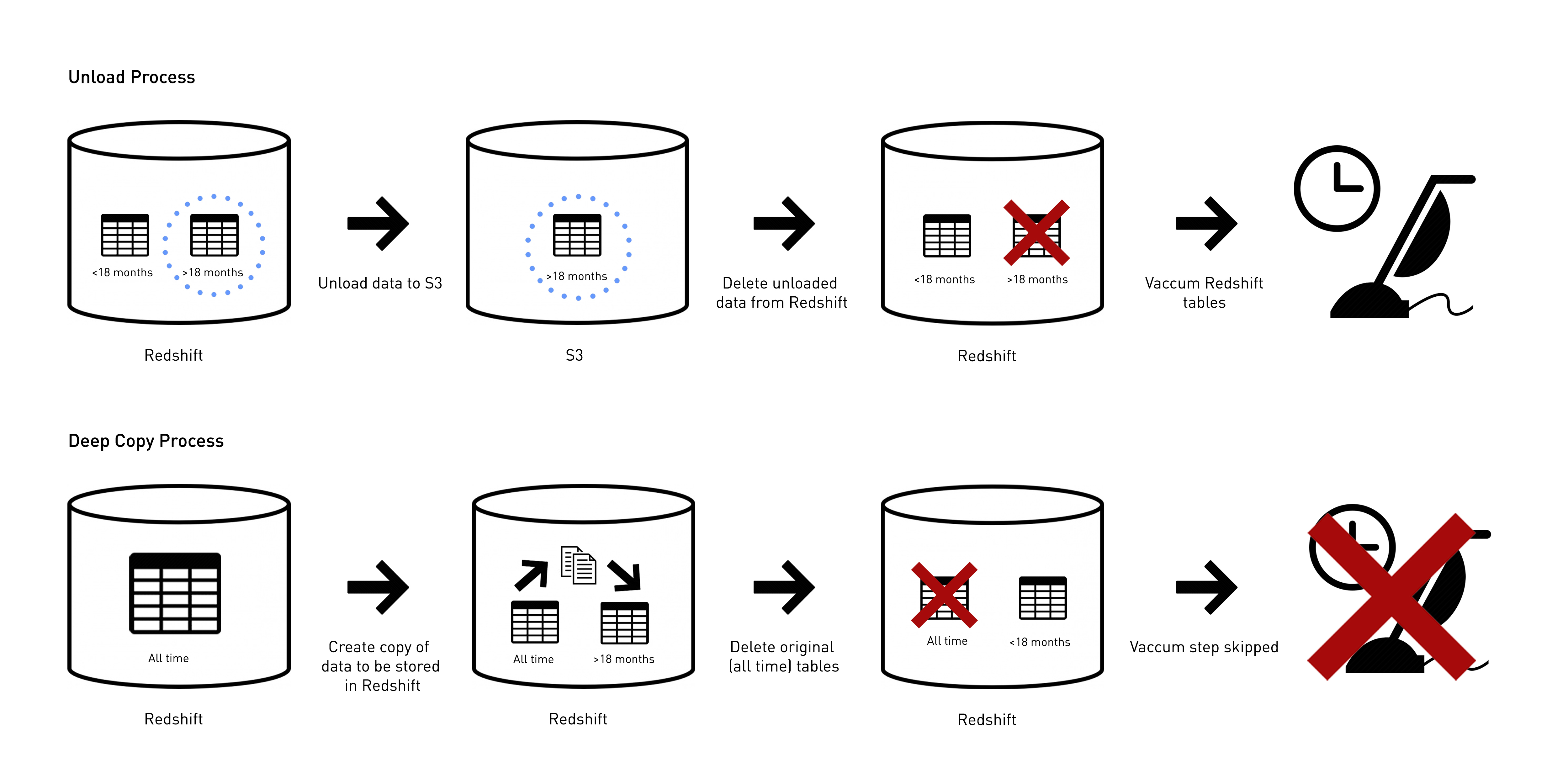
Our first idea was to unload data older than 18 months to S3 (to then be transferred to glacier) followed by deleting it directly from the tables in Redshift.
BEGIN;
-- unload data from table to S3
UNLOAD
(SELECT * FROM table_name
WHERE root_tstamp < DATE_ADD('month', -18, CURRENT_DATE))
to 's3 location'
CREDENTIALS 'aws_access_key_id=<KEY HERE>;aws_secret_access_key=<SECRET KEY>'
DELIMITER '|' NULL AS 'null_string' ESCAPE;
-- delete data unloaded to S3 from table
DELETE FROM unload_table
WHERE collector_tstamp < DATE_ADD('month', -18, CURRENT_DATE);
COMMIT;
The process outlined above worked fine however we still needed to run a vaccum statement to reclaim the lost disk space. With over 4TB of data to resort, our vacuum queries had been running for nearly a whole day and weren’t even 2% complete - unloading was clearly a no go!
Epiphany
Back at the drawing board, we realised that there was no need to unload data from Redshift to S3 as all Snowplow data is already stored there in shredded good (which can be used to reload archived data back into Redshift). With this in mind it was clear that using deep copy statements was our solution! The new process would now play out as follows:
- For each table, create a copy in Redshift which only includes the most recent 18 months.
- Delete the original version of the table which includes data older than 18 months.
- Rename the new table to replace the old one.
Taking this approach eliminated the need for us to perform a vacuum as we were simply copying already sorted data within the client’s Redshift cluster - improving efficiency exponentially! To put this into perspective, applying the deep copy transaction to atomic.events on our own data took 5.91 seconds.
Deep Copy Approach
BEGIN;
-- renaming the table prior to dropping it
ALTER TABLE table_name RENAME TO table_name_old;
-- creating an empty version of the table
CREATE TABLE IF NOT EXISTS table_name_new (table definition);
-- populating the empty table with the most recent 18 months of data from the old table
INSERT INTO table_name_new (SELECT * FROM table_name_old WHERE root_tstamp > DATE_ADD('month', -18, CURRENT_DATE));
-- renaming the new table to replace the table dropped
ALTER TABLE table_name_new RENAME TO table_name;
-- changing the owner of the table
ALTER TABLE table_name OWNER to owner_username;
COMMIT;
-- dropping the table with data older than 18 months
DROP TABLE table_name_old;
As we had to automate and apply the deep copy process to 25 tables, we used SQL Runner to execute the queries in parallel.
Example SQL Runner Playbook
The example below executes the unload transaction across three demo tables in the atomic schema. Selecting schema and backupWindow as variables allows us to easily control them without altering each individual SQL file.
:targets:
- :name: "Test Redshift"
:type: redshift
:host: host location
:database: database name
:port: 0000
:username: Test
:password: {{secret "redshift-password"}}
:ssl: false # SSL disabled by default
:variables:
:backupWindow: "18"
:schema: "atomic"
:steps:
- :name: 00-table_name
:queries:
- :name: 00-table_name
:file: sql file path
:template: true
:steps:
- :name: 01-table_name
:queries:
- :name: 01-table_name
:file: sql file path
:template: true
:steps:
- :name: 02-table_name
:queries:
- :name: 02-table_name
:file: sql file path
:template: true
In order for the playbook to communicate with the associated SQL files, some code alterations compared to the example outlined earlier are required:
SQL With Playbook Association
BEGIN;
-- renaming the table prior to dropping it
ALTER TABLE {{.schema}}.table_name RENAME TO table_name_old;
-- creating an empty version of the table
CREATE TABLE IF NOT EXISTS {{.schema}}.table_name_new (table definition);
-- populating the empty table with the most recent 18 months of data from the old table
INSERT INTO {{.schema}}.table_name_new ('SELECT * FROM {{.schema}}.table_name_old WHERE root_tstamp > DATE_ADD(\'month\', -{{.backupWindow}}, CURRENT_DATE)');
-- renaming the new table to replace the table dropped
ALTER TABLE {{.schema}}.table_name_new RENAME TO table_name;
ALTER TABLE {{.schema}}.table_name OWNER to owner_name;
COMMIT;
-- dropping the table with data older than 18 months
DROP TABLE {{.schema}}.table_name_old;
Deep Copying Tables With A Primary Key
When performing a deep copy on a table with a primary key, make sure that the constraint is dropped before inserting an empty table with the same definition into Redshift. An example of a table with a primary key is atomic.events.
Deep Copy With Constraint Drop
BEGIN;
-- renaming the table prior to dropping it
ALTER TABLE {{.schema}}.table_name RENAME TO table_name_old;
-- removing the primary key from the drop table
ALTER TABLE {{.schema}}.table_name_old DROP CONSTRAINT constraint_name;
-- creating an empty version of the table
CREATE TABLE IF NOT EXISTS {{.schema}}.table_name_new (table definition);
-- populating the empty table with the most recent 18 months of data from the old table
INSERT INTO {{.schema}}.table_name_new ('SELECT * FROM {{.schema}}.table_name_old WHERE root_tstamp > DATE_ADD(\'month\', -{{.backupWindow}}, CURRENT_DATE)');
-- renaming the new table to replace the table dropped
ALTER TABLE {{.schema}}.table_name_new RENAME TO table_name;
ALTER TABLE {{.schema}}.table_name OWNER to owner_name;
COMMIT;
-- dropping the table with data older than 18 months
DROP TABLE {{.schema}}.table_name_old;
In Too Deep Copying
A potential downfall of running a deep copy process is the requirement of using less than 50% disk space prior to starting it. This is because the full set of desired data has to be copied and stored temporarily before the tables that include the data to be archived can be deleted.