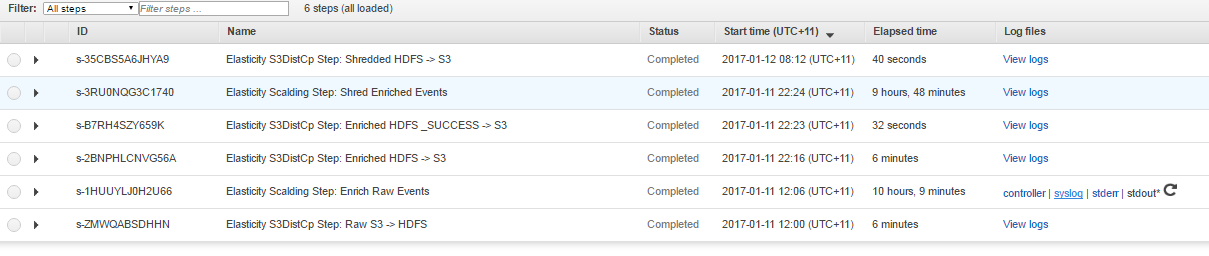
I ETL-EMR batch job is trying to process 150K files on S3 and Step 2 is taking way too long, it has completed in 20 hours! using this configuration below. I came across your small file post.
Do you think that is the issue, also where do I insert the S3Distcopy consolidation task, just looking for a specific pointer please, thanks for your help.
Current EMR Config:
jobflow:
master_instance_type: r3.xlarge
core_instance_count: 2
core_instance_type: r3.xlarge
task_instance_count: 3 # Increase to use spot instances
task_instance_type: r3.xlarge
task_instance_bid: 0.015 # In USD. Adjust bid, or leave blank for non-spot-priced (i.e. on-demand) task instances
bootstrap_failure_tries: 3 # Number of times to attempt the job in the event of bootstrap failures
versions:
hadoop_enrich: 1.7.0 # Version of the Hadoop Enrichment process
hadoop_shred: 0.9.0 # Version of the Hadoop Shredding process
hadoop_elasticsearch: 0.1.0
Nothing stood out in the logs, I think it is the Hadoop small file issue mentioned in post from @alex I attached in my original post.
Only errors-
log4j:ERROR Failed to rename [/mnt/var/log/hadoop/steps/s-1HUUYLJ0H2U66/syslog] to [/mnt/var/log/hadoop/steps/s-1HUUYLJ0H2U66/syslog.2017-01-11-01].
That’s a pretty significant number of files. Is that for a large data range or is data being sinked on a very regular basis?
I imagine the time taken just to copy 47K files from S3 to HDFS would be reasonable in of itself - I wonder if it’s worth considering merging some LZO files together to create larger files rather than attempting to process 47K all at once. Thoughts @alex?
Based off this slide for EMR deep dive (slide 25) - bigger files = better performance.
Make sure to compress (we use the lzo), and dont forget to increase your timeout/number of records to accommodate the file size.
47k pairs -> what file size / time / # of records are you at for syncing with s3?
You also want to avoid “small file problem” that can have a negative effect not only on s3 copy but on EMR processing as well.
The files are from about 2 weeks of activity on a very low volume site. I am assuming each LZO is one event (about 8K - 900K each compressed) and 47K events per day is not that crazy (I would imagine for even a daily volume).
Question - Where do I add a step in the EMR job to S3distcpy and compress the files into few large one as stated by @alex in his post here
Don’t the files get aggregated into 128mb chunks in the S3DistCp step? The large number of files wouldn’t explain why the EMR process took 20 hours to run, right?
Sorry @alex I am unable to find that setting to adjust the buffer on Snowplow. And it seems Kinesis (streams) doesn’t allow for that I know the Kinesis Firehose does. Am I totally off track here?