Hi,
we are currently upgrading out shredder and rdbloader from 0.19.0 to 2.0.0.
We have been using this playbook.json
{
"type": "CUSTOM_JAR",
"name": "RDB Shredder",
"actionOnFailure": "CANCEL_AND_WAIT",
"jar": "command-runner.jar",
"arguments": [
"spark-submit",
"--class", "com.snowplowanalytics.snowplow.rdbloader.shredder.batch.Main",
"--master", "yarn",
"--deploy-mode", "cluster",
"s3://snowplow-hosted-assets-eu-central-1/4-storage/rdb-shredder/snowplow-rdb-shredder-2.0.0.jar",
"--iglu-config", "{{base64File "resolver.json"}}",
"--config", "{{base64File "config.hocon"}}"
]
}
We have already changed the class name to rdbloader.shredder.batch.Main.
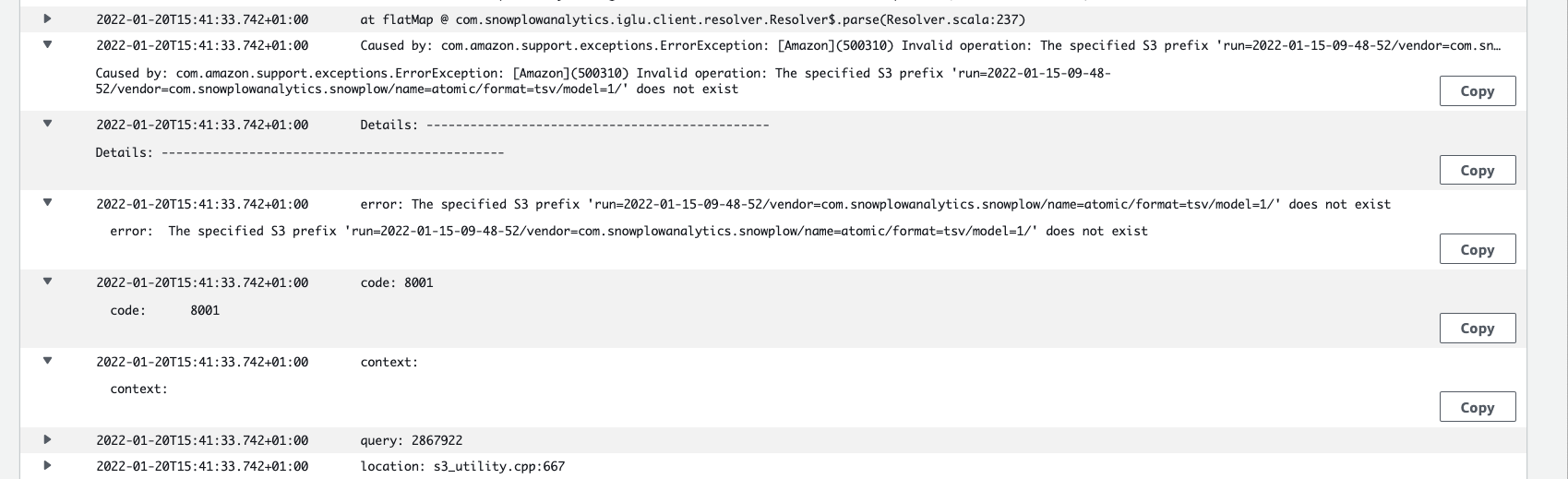
However, the shredding job now fails at decoding the config files:
- Unable to parse the configuration: DecodingFailure at .input: String.
Usage: snowplow-rdb-shredder-2.0.0 --iglu-config <<base64>> [--duplicate-storage-config <<base64>>] --config <config.hocon>
Spark job to shred event and context JSONs from Snowplow enriched events
Options and flags:
--help
Display this help text.
--iglu-config <<base64>>
Base64-encoded Iglu Client JSON config
--duplicate-storage-config <<base64>>
Base64-encoded Events Manifest JSON config
--config <config.hocon>, -c <config.hocon>
base64-encoded config HOCON
We are using the new config templates for shredder and rdbloader.
{
"name": "myapp",
"id": "4113ba83-2797-4436-8c92-5ced0b8ac5b6",
"region": "eu-west-1",
"messageQueue": "SQS_QUEUE",
"shredder": {
"input": "SP_ENRICHED_URI",
"output": "SP_SHREDDED_URI"
"compression": "GZIP"
},
"formats": {
"default": "JSON",
"json": [ ],
"tsv": [ ],
"skip": [ ]
},
"jsonpaths": "s3://snowplow-schemas-STAGE/jsonpaths/",
"storage": {
"type": "redshift",
"host": "REDSHIFT_ENDPOINT",
"database": "sp_redshift_database",
"port": 5439,
"roleArn": "arn:aws:iam::AWS_ACCOUNT_NUMBER:role/REDSHIFTLOADROLE",
"schema": "atomic",
"username": "REDSHIFT_USER_NAME",
"password": "DB_REDSHIFT_PASSWORD",
"jdbc": {"ssl": true},
"maxError": 10,
"compRows": 100000
},
"steps": ["analyze"],
"monitoring": {
"snowplow": null,
"sentry": null
}
}
and a resolver.json
{
"schema": "iglu:com.snowplowanalytics.iglu/resolver-config/jsonschema/1-0-0",
"data": {
"cacheSize": 500,
"repositories": [
{
"name": "S3-schemas-registry",
"priority": 0,
"vendorPrefixes": ["com.,myapp"],
"connection": {
"http": {
"uri": "SP_SCHEMA_URI"
}
}
},
{
"name": "Iglu Central",
"priority": 1,
"vendorPrefixes": [ "com.snowplowanalytics" ],
"connection": {
"http": {
"uri": "http://iglucentral.com"
}
}
},
{
"name": "Iglu Central - Mirror 01",
"priority": 2,
"vendorPrefixes": ["com.snowplowanalytics"],
"connection": {
"http": {
"uri": "http://mirror01.iglucentral.com"
}
}
}
]
}
}
- We are using a static schema repo hosted on s3? Do we need to use iglu-server?
- Is --duplicate-storage-config <>
Base64-encoded Events Manifest JSON config optional?