Exposing data from Redshift can be a pain when many dashboarding tools don’t support it OOB. As big R users we often generate reports out of RStudio using rmarkdown and knitr for performing useful analytics on the data. But for some reports it’s just impractical as clients want to explore their up-to-date data in an accessible dashboard. Since dashboards aren’t a core part of our business we couldn’t justify thousands of dollars a year for BI tools like Periscope or Tableau. Meanwhile other services like Slemma were OK but offered limited control and slow reports.

Introducing Airbnb Caravel
Airbnb decided to roll their own interactive BI solution and open source it. It has a large following on Github thanks to it being built on Python, Flask, Pandas and SQLAlchemy. I think the Snowplow community will love it for:
- Diverse set of visualisations to choose from
- Create and manage users with fine-grained permissions
- Connect to Redshift and many other DBs supported by SQLAlchemy
- Caching for taxing queries
- JSON/CORS support for exposing Redshift data across domains
- Interactively query your Snowplow events from the web
The feature set is still on the basic side but it’s really promising. Whereas before I would jump into Google Analytics to answer quick questions of web analytics data, we now use Caravel to access every single event in Redshift.

Getting started
You have two options:
I find it’s simplest to just manage the whole process with Docker containers, because you may struggle getting the environment ready with all the dependencies in Python. Note: If you’re installing this directly you will need to install the sqlalchemy-redshift package to connect to Redshift using: pip install sqlalchemy-redshift.
1, Fire up an instance and make sure you have Docker installed: https://docs.docker.com/engine/installation/linux/ubuntulinux/
2, Run the Docker container automatically managed by amancevice on Github (it’s an automated build kept up to date and contains everything you need to access Redshift out of the box). If you’re just trialling Caravel for the first time you may like to use the SQLite DB before committing to MySQL:
docker run --detach --name caravel \
--env SECRET_KEY="mySUPERsecretKEY" \
--env SQLALCHEMY_DATABASE_URI="sqlite:////home/caravel/db/caravel.db" \
--publish 8088:8088 \
--volume ~/caravel:/home/caravel/db \
amancevice/caravel
3, Initialise the Caravel DB by running the init command and answer some questions to setup your admin user details:
docker exec -it caravel caravel-init
4, Make sure you open up port 8080 and you should be able to login to your Caravel instance. Boom.
5, After logging in, browse to “Sources” > “Databases” and add your Redshift DB to Caravel and Test the connection:


It should follow this format: redshift+psycopg2://username@host.amazonaws.com:5439/database
As always, make sure Redshift is accessible by the new host. You’ll know it’s working when you get a successful message upon hitting “Test connection”
6, Next, you’ll need to define your tables. Under the “Sources” menu, hit “Tables” and add a new row:
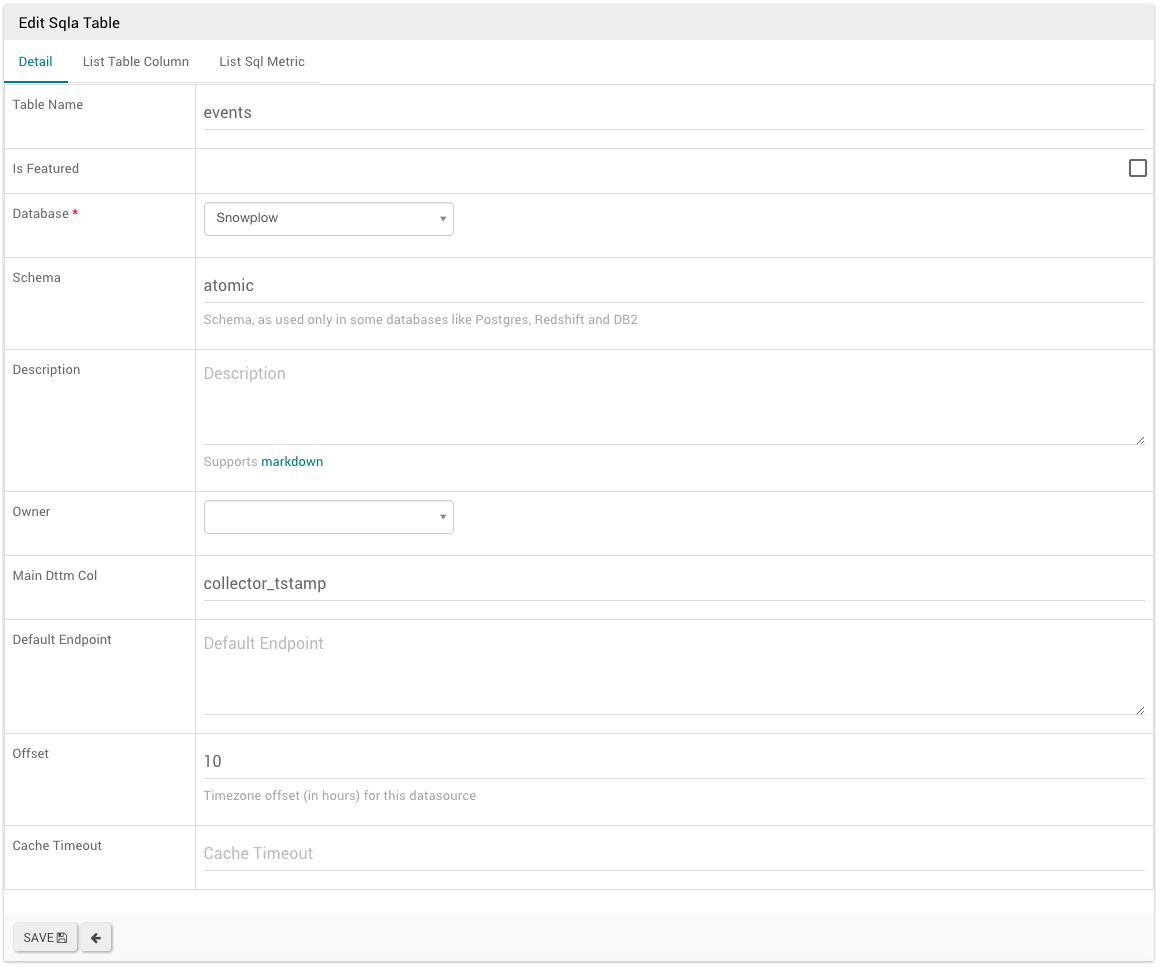
To get started you may like to add your atomic.events table:
Table name: events
Database: snowplow (Or whatever you named the DB you just created)
Schema: atomic
Main dttm: collector_tstamp
Offset: However many hours you want to offset from UTC time.
If Caravel can’t find the table, make sure your user permissions allow access to the table and failing that, check that the atomic schema is in Redshift’s search path - you’ll need to modify your cluster parameters as described here by Redshift.
7, Once your table is saved, you’ll want to edit the table and let Caravel know how to treat each column. I won’t cover this here as it should be fairly self-explantory:

This affects which variables will be available to you in Exploration mode.
8, Now you have all your data setup, you should be ready to create slices for a dashboard and begin exploring your data interactively. Just browse to your newly created events table and open it, right away it will show you a table with a count:

You can perform simple aggregations in the table using Group By and count distinct:

But most importantly you can change the visualisation to any number of the built in charts:

How awesome is that!
9, When you’re finished exploring your data and you want to save it as a slice for viewing later, just hit save and add it to a dashboard.
Voila… you’ve now got all your Snowplow data at your fingertips!
Exciting new features are coming soon to Caravel
- Tabbed SQL editor to write and run queries directly in a web interface
- Table joins support coming
Let me know what you think of this guide and if you run into any issues, just let me know.