As part of our drive to make the Snowplow community more collaborative and widen our network of open source contributors, we will be regularly posting our proposals for new features, apps and libraries under the Request for Comments section of our forum. You are welcome to post your own proposals too!
This Request for Comments is to port the Snowplow event pipeline to run natively on Microsoft Azure. By natively, we mean that Snowplow should be tailored to make best use of Azure-specific products and services.
1. Background on Azure
Azure is a cloud computing service by Microsoft, equivalent in scope and ambition to Amazon Web Services or Google Cloud Platform. The Azure offering has been steadily built up since its launch in February 2010, and now comprises over 600 in-house and third-party compute- and data-oriented services.
Azure is particularly popular in finance, manufacturing and gaming - see the Azure case studies for more information.
2. Snowplow platform compatibility so-far
A brief recap on Snowplow’s current platform support:
- At the start of 2012 we launched the Snowplow batch pipeline running on AWS using EMR, S3 and associated service
- In February 2014 we launched the Snowplow real-time pipeline running on AWS, making heavy use of Amazon Kinesis
- In November 2016 we released an alpha of the Snowplow real-time pipeline ported to run on-premise using Apache Kafka
As you can see, Snowplow has been closely tied to AWS since its inception over five years ago. However, while we do make heavy use of leading AWS services such as Redshift, EMR and Kinesis, in fact little of the Snowplow processing logic is AWS-specific.
3. Cross-platform Snowplow
The cloud services market has changed over the past few years: while AWS continues to be the market leader, GCP and Azure are growing fast, launching their own “hero” services such as Google BigQuery and Azure Data Lake Analytics. Meanwhile, a new generation of infrastructure technologies like Kafka, Kubernetes and OpenShift are helping to define a kind of “common runtime” for on-premise software deployments.
What does all this mean for Snowplow? A key priority for us in 2017 is extending our software to run on these other core runtimes: Google Cloud Platform, Microsoft Azure and on-premise. Cross-platform Snowplow should help:
- Broaden Snowplow adoption - we want Snowplow to be available to companies on whichever cloud or on-premise architecture they have adopted
- Deliver “pipeline portability” - investing in Snowplow shouldn’t lock you into a specific cloud platform indefinitely. You should be able to bring the core capabilities - and data - of your Snowplow pipeline with you when you migrate from one cloud to another
- Enable “hybrid pipelines” - you use AWS everywhere but your data scientists love BigQuery? You want a lambda data processing architecture with Azure HDInsight plus Kinesis Analytics? We want to support Snowplow pipelines which connect together best-in-class services from different clouds as required
Stay tuned for our Google Cloud Platform RFC, coming in early June.
Let’s now look specifically at Microsoft Azure support for Snowplow.
4. Snowplow and Azure
To date we have not experimented with Microsoft Azure at Snowplow - however we have had some customer/user interest in running Snowplow on Azure, and had a lively snowplow/snowplow GitHub issue discussing the possibilities for porting to Azure.
Following that initial discussion, we connected with the global Microsoft DX team for Azure, who have been able to review an early draft of this RFC.
Considering a port to a new cloud, we have to answer a few key questions:
- What cloud-native services does this cloud provide which could be used for the various components of Snowplow?
- What services shall we use?
- How do we implement a pipeline from these services?
- What components do we need to extend or create?
Answering these questions starts by taking an inventory of the relevant Azure services.
5. Inventory of relevant Azure services
The relevant Azure services are:
| Snowplow component(s) | AWS service(s) | Azure service(s) | Description |
|---|---|---|---|
| Unified log | Amazon Kinesis | Event Hubs | "Cloud-scale telemetry ingestion from websites, apps and any streams of data" |
| Unified log & Storage | Amazon S3 | Azure Blob Storage | "Massively scalable object storage for unstructured data" |
| Event collection | AWS Elastic Beanstalk | Web Apps (App Service) | "Create and deploy mission-critical web apps that scale with your business" - https://azure.microsoft.com/en-us/services/app-service/web/ |
| Event collection | AWS Elastic Load Balancing & AWS Auto Scaling | Virtual Machine Scale Sets | "Manage and scale up to thousands of Linux and Windows virtual machines" |
| Event enrichment | Amazon Elastic MapReduce | Azure HDInsight | "A cloud Spark and Hadoop service for your enterprise" |
| Event enrichment | Kinesis Client Library | Microsoft Azure Event Hubs Client for Java | "Allows for both sending events to and receiving events from an Azure Event Hub" |
| Storage | - | Azure Data Lake Store | "A no-limits data lake to power intelligent action" |
| Event data modeling & Analytics | Amazon Redshift | Azure SQL Data Warehouse | "Elastic data warehouse-as-a-service with enterprise-class features" |
| Event data modeling & Analytics | AWS Lambda | Azure Functions | "Process events with serverless code" |
| Event data modeling & Analytics | AWS Athena / Redshift Spectrum | Azure Data Lake Analytics | "Distributed analytics service that makes big data easy" |
Sources: Directory of Azure Cloud Services; AWS to Azure services comparison.
Some of the above services are relatively similar to their AWS counterparts - for example, Azure HDInsight is a relatively close proxy to EMR, and Azure Event Hubs have similar semantics to Apache Kafka or Amazon Kinesis.
However, we also see some distinctive “hero” services here:
5.1 Azure Data Lake Store
Azure Data Lake Store (ADLS) has no direct equivalent in AWS - think of ADLS as like Amazon S3 but re-architected to support massive scale analytics on the data. This is hugely exciting for Snowplow users - it brings the possibility of extremely fast ad hoc analytics on your entire Snowplow enriched event archive.
In theory we could use ADLS everywhere where we use S3 in the AWS pipeline. However, ADLS is more expensive than Azure Blob Storage.
5.2 Azure Data Lake Analytics
Azure Data Lake Analytics is an on-demand analytics service that can run queries against huge data volumes stored in Azure.
It is somewhat similar to AWS Athena (Presto), but far fuller featured - for example, Data Lake Analytics’s U-SQL query language is highly programmable and extensible in C#, Python and even R.
6. Pipeline implementation
When we look to adapt Snowplow to a new cloud, we want our new implementation to:
- Preserve the “essence” of Snowplow, including all of our core capabilities. At a bare minimum, it should be possible to migrate to or from the new cloud without losing access to your Snowplow event archive
- Be idiomatic to the new cloud’s capabilities, services and recommended design patterns
- Make good use of the new cloud’s “hero services” - Snowplow should avoid using the “lowest common denominator” services across each cloud
Drawing on our Snowplow Lambda architecture, here is a proposed implementation on Azure which covers both batch and real-time use cases:
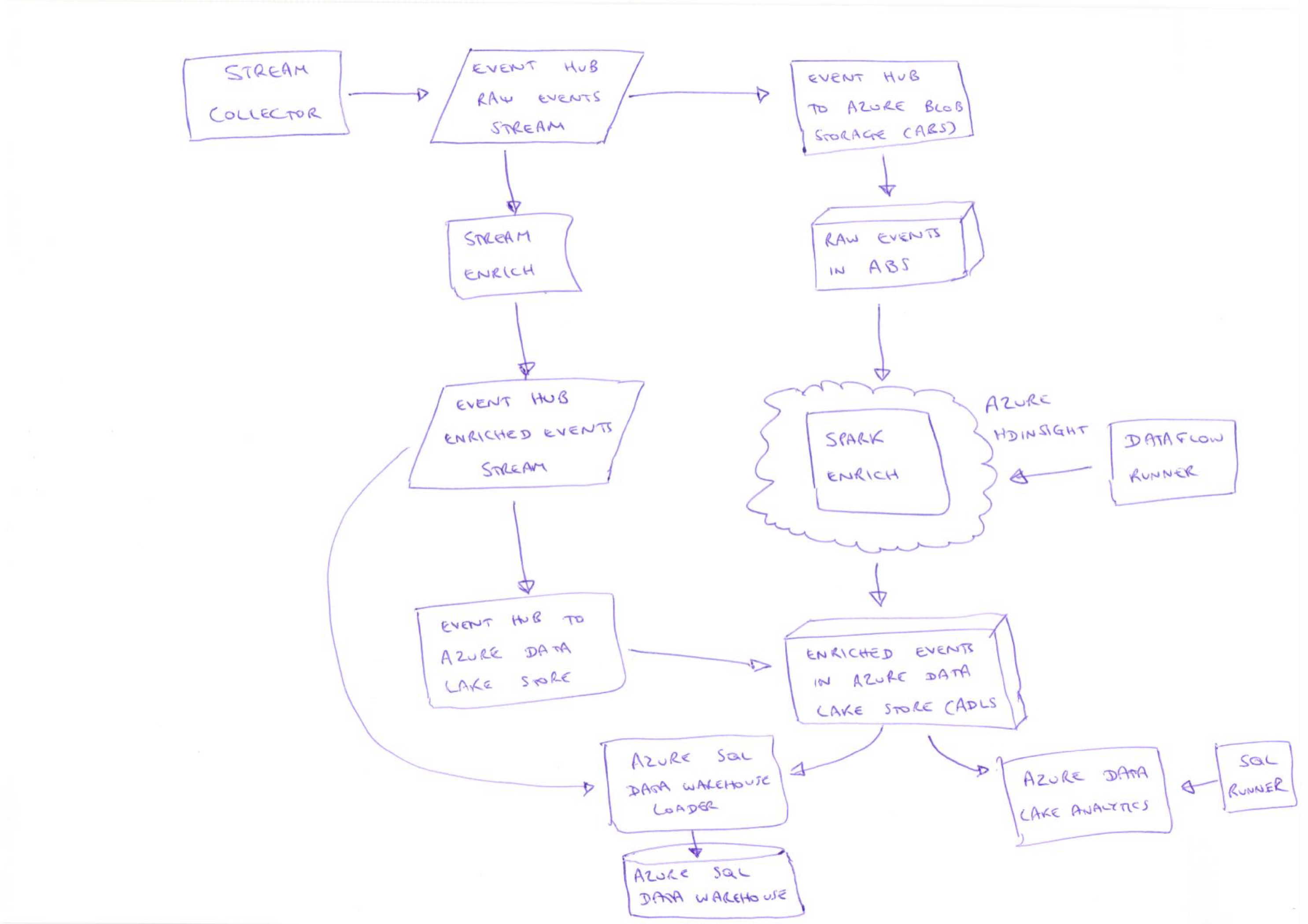
There are a set of assumptions implicit in this design:
6.1 Using Azure Event Hubs as our unified log
The Snowplow batch pipeline on AWS uses S3 as its unified log; the Snowplow real-time pipeline uses Kinesis. If we were starting building Snowplow on AWS today, it’s unlikely we would use a blob storage like S3 as our unified log again.
Azure Event Hubs are a close mapping onto Kinesis - so we will settle on Event Hubs as our unified log service on Azure.
6.2 Extending the Scala Stream Collector, not the Clojure Collector
It should be relatively straightforward for us to extend the Scala Stream Collector to support an Event Hub sink. This is the simplest way of bringing Snowplow event collection to Azure, and is also compatible with our Replacing the Clojure Collector RFC.
We would likely run Scala Stream Collector in Azure using Virtual Machine Scale Sets (VMSS), not Web Apps.
Web Apps are a PaaS-level abstraction, somewhat similar to Elastic Beanstalk, and we have found that Beanstalk-level abstractions have too much “magic” for predictable event collection. By contrast, VMSS is closer to the AWS Auto Scaling that works so well for the Scala Stream Collector on AWS.
6.3 Continuing separation of Stream Enrich and Spark Enrich
We plan on maintaining the separation of Stream Enrich and Spark Enrich, rather than trying for example to harmonize these into a single component, such as Spark (Streaming) Enrich. This is driven by a few factors:
- This should minimize the amount of extra code that needs to be added to Spark Enrich
- This should provide more event processing flexibility on the real-time pipeline - the micro-batching behavior of Spark Streaming is quite restrictive in how it can buffer events
- This should reduce operational complexity for the real-time pipeline - because it won’t be dependent on a whole Spark runtime
- This should make it easier to support hybrid clouds - because Stream Enrich can read from one unified log technology and write to another
6.4 Using Blob Storage for raw events, Data Lake Store for enriched events
Azure Data Lake Store (ADLS) is an exciting technology and the temptation is to use it everywhere as our Amazon S3 storage equivalent. However, ADLS is more expensive than simple Azure Blob Storage, and in practice the raw events are rarely re-used - because full re-processings of a Snowplow raw event archive are infrequent.
Therefore, we propose:
- Using Azure Blob Storage for the infrequently used raw event (aka collector payloads) archive
- Using Azure Data Lake Store for the frequently queries enriched event archive
7. New and extended components
With these assumptions in place, here are some implementation notes on the particular components we need to create or extend:
7.1 Stream Enrich
For the real-time pipeline, we could embed the Microsoft Azure Event Hubs Client for Java in our Stream Enrich application, alongside the Kinesis Client Library (KCL).
The Microsoft Azure Event Hubs Client for Java seems to be less feature-rich than the Kinesis Client Library (KCL) - but this is probably a good thing; beyond the valuable checkpointing and leader election capabilities in the KCL, there is a lot of complexity which we would like to avoid, such as the way that a single Stream Enrich process can run multiple shard workers internally.
The Java Client uses Azure Blob Storage for checkpointing and leader election (equivalent to how the KCL uses DynamoDB).
7.2 Spark Enrich and Dataflow Runner
Spark Enrich is the new name for our Scala Hadoop Enrich component. It should be possible to run our batch event processing job to run on HDInsight, with a few changes:
- Remove any AWS-isms around Spark Enrich’s configuration and file storage
- Extend Dataflow Runner to support kicking off jobs on Azure HDInsight (see Dataflow Runner issue #22)
7.3 Event Hub to Blob Storage and Data Lake Store
Azure Event Hubs have a built-in Archive capability but:
- This seems to only support Azure Blob Storage, not Azure Data Lake Store
- The Avro-based format is incompatible with the Twitter Elephant Bird Protobuf-based format that Snowplow uses for raw event archiving
Therefore, we may need to extend or port Kinesis S3 to add support for:
- Sinking raw events from an Event Hubs stream to Azure Blob Storage in Elephant Bird format
- Sinking enriched events to Azure Data Lake Store
7.4 Azure Data Lake Analytics and a Snowplow .NET Analytics SDK
Once the Snowplow enriched events are stored in Azure Data Lake Store, we would like to run data modeling and analytics processes on this data using Azure Data Lake Analytics.
The current Snowplow enriched event format is quite hard to work with - we normally recommend interfacing with those events using our Scala or Python Analytics SDKs. With Azure Data Lake Analytics we could do something similar:
- Port our Scala Analytics SDK to a .NET Analytics SDK
- Write a custom extractor for Data Lake Analytics that embeds our .NET Analytics SDK
- Use this extractor from U-SQL to run queries on Snowplow enriched events
7.5 Azure SQL Data Warehouse Loader
We can identify two requirements for loading Azure SQL Data Warehouse:
- In the batch pipeline, loading each new run of Snowplow enriched events
- In the real-time pipeline, loading incoming enriched events as fast as possible
Given that Azure SQL Data Warehouse does not seem to support streaming inserts per the load documentation, it would make sense to use Spark Streaming for this loader. This loader would operate in two modes:
- For the batch pipeline, operate in standard Spark mode, reading enriched events from Azure Data Lake Store
- For the real-time pipeline, operate in Spark Streaming mode, reading direct from the Events Hubs enriched events stream
7.6 SQL Runner
Many of our users use SQL Runner to perform event data modeling on the events once in Redshift.
In an Azure world, Snowplow users might want to run T-SQL scripts against Azure SQL Data Warehouse, or U-SQL scripts against Azure Data Lake Analytics. To enable this, we would extend SQL Runner, see issue #98 and issue #99 in that project’s repo.
8. Sequencing
There is a huge amount of new development involved in the above proposal! Here is a first attempt at phasing this work:

The rationale for splitting the work into these three phases is as follows:
8.1 Phase 1: Real-time pipeline through to Azure Data Lake Analytics
This is clearly a broadly-scoped phase one, but delivering this allows Snowplow users to:
- Build their own real-time apps on top of the real-time Snowplow event stream in Azure
- Do ad hoc data modeling and analytics on their Snowplow data in Azure Data Lake Store, using Data Lake Analytics
This covers off two of the key Snowplow use cases from the start.
8.2. Phase 2: batch processing of Snowplow data
Adding in the batch pipeline in Spark Enrich lets a Snowplow user do two things:
- Migrate a Snowplow event archive from AWS to Azure
- Perform a full historical re-processing of all their Snowplow raw data on Azure
8.3 Phase 3: loading Azure SQL Data Warehouse
Although loading Redshift is a mainstay of the Snowplow pipeline on AWS, we propose leaving this to the third development phase for Azure. There are two main reasons for this:
- We believe that most of the Redshift-style use cases can be covered with Azure Data Lake Analytics in phase 1
- Adding support for a new relational-columnar database to Snowplow is complex. There is a lot of foundational refactoring work we want to do to our existing Redshift load process first before tackling this
9. REQUEST FOR COMMENTS
This RFC represents a hugely exciting new runtime for Snowplow, and so we welcome any and all feedback from the community. As always, please do share comments, feedback, criticisms, alternative ideas in the thread below.
In particular, we would appreciate any experience or guidance you have from working with Microsoft Azure in general or services such as HDInsight or Azure Data Lake Analytics in particular. We want to hear from you whether your experience comes from data engineering/analytics/science work on Azure, or general workloads!


